A Wrapper Class of PU classification for scikit-learn's Probabilistic Classifiers
Notations :
: random vector drawn from
: random variable which indicates positive (1) or negative (-1) drawn from
: random variable which indicates labeled (1) or unlabeled (0) drawn from
i.i.d. sample drawn from
PU classification is a framework for learning classifiers from positive and unlabeled data. This is firstly introduced by Elkan and Noto, “Learning Classifiers from Only Positive and Unlabeled Data” (ACM 2008). The goal of traditional classification problem is to estimate from i.i.d. sample . On the other hand, In the setting of PU classification, our goal is to estimate from .
Elkan and Noto showed that under some assumptions, we can express as,
We can estimate from , and can be estimated by cross-validation.
In this article, I introduce a wrapper class of PU classification for scikit-learn’s classifiers, puwrapper.py. We employ Elkan’s method in this wrapper class.
All we need to use this class is wrap the scikit-learn’s probabilistic classifiers like this:
from puwrapper import PUWrapper
from sklearn.linear_model import LogisticRegression
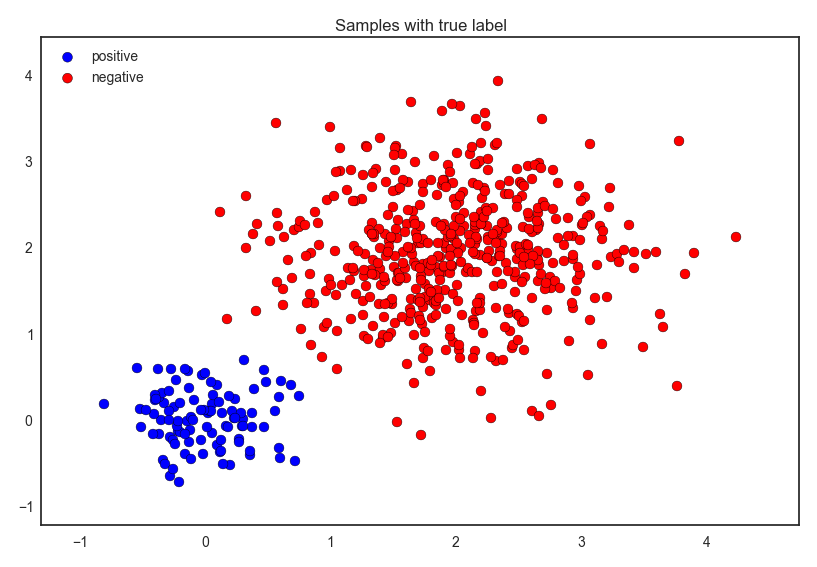
clf=PUWrapper(LogisticRegression())Now let’s see the demo. The figure below is data with true labels.
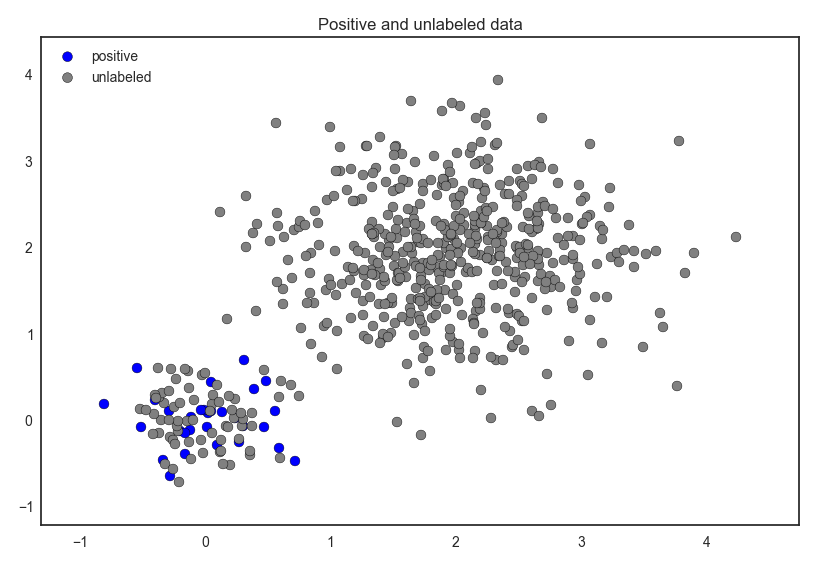
Actually, we observe the following data:
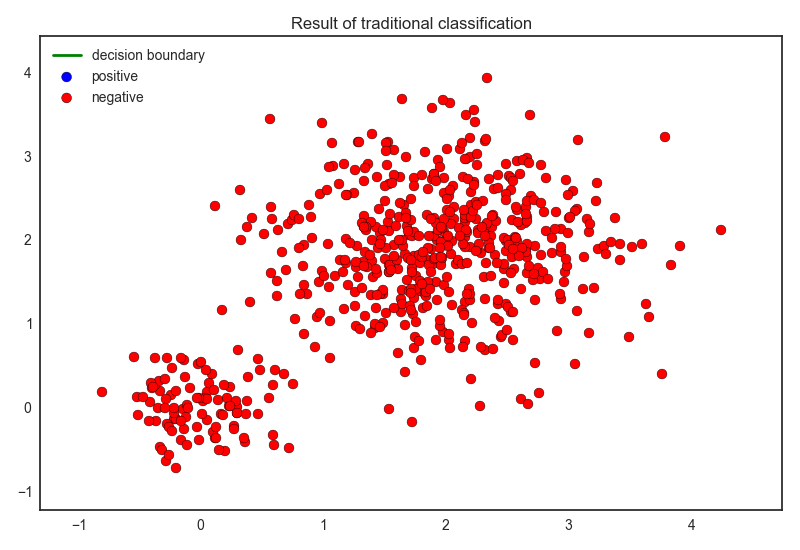
First let’s apply ordinal Logistic Regression model (Note that we use positive’s F1-value as score function of cross-validation since the data is highly imbalanced). The result is shown below.
Finally we applied Elkan’s method. The result is shown below.
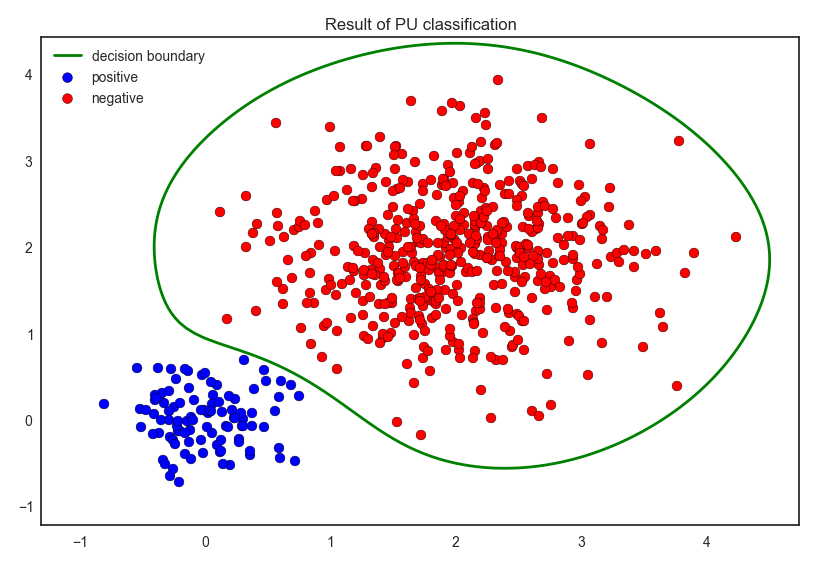
As you can see that, we could classify the data into positive and negative accurately. The demo code is available here: pu_demo.py